The Gradient-Causal Gap:
When Attribution Fails Interpretability
Removing `important' high-gradient components from a neural network can improve generalization, while removing `unimportant' low-gradient components can destroy it. We demonstrate this paradox by formalizing the Gradient-Causal Gap. While parameter-normalized gradient magnitude and causal importance align on a simpler task ($\rho=0.59$, reversal), this relationship collapses on a harder task ($\rho=0.07$, sorting), with four seeds exhibiting negative correlation (as low as $\rho=-0.34$). Unlike prior input-level sanity checks that rely on correlational evidence, we validate this failure causally: ablating low-gradient `Hidden Heroes' annihilates OOD accuracy ($-64\%$), while ablating high-gradient `Gradient Bloats' causes task-dependent damage, ranging from marginal ($-9.5\%$) where alignment has collapsed to severe ($-27\%$) where alignment remains moderate, confirming that gradient magnitude is an unreliable proxy regardless of direction. Critically, the gap is not random noise but a structured phenomenon with predictable layer-wise organization, worsening as task complexity increases. These findings suggest that gradient-based attribution, widely used in NLP interpretability and model auditing, may systematically misidentify the components that drive model behavior.
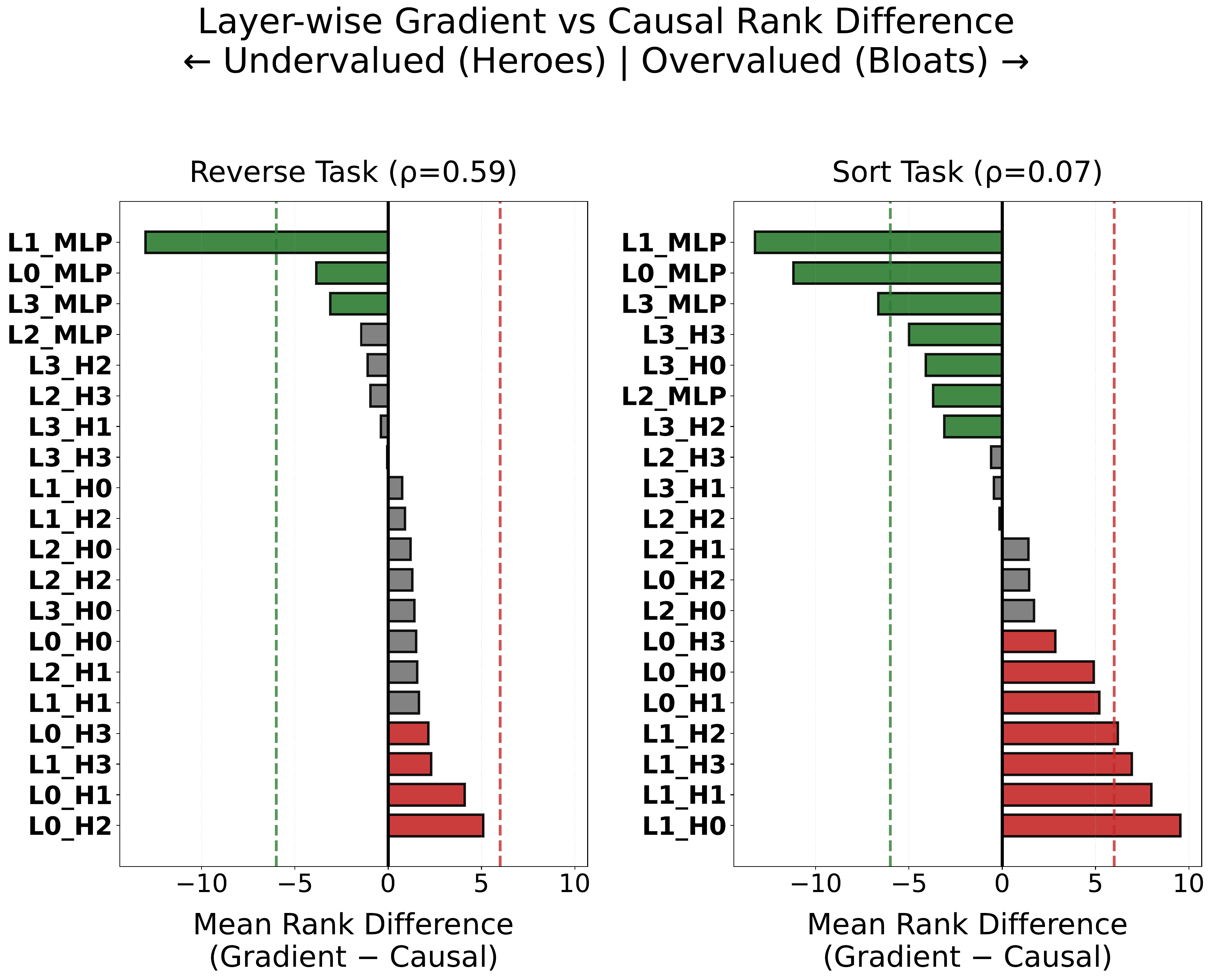
Figure 1. Mean rank difference (Gradient − Causal) per component. Green = Hidden Heroes (undervalued by gradients). Red = Gradient Bloats (overvalued). Sort task (right) shows near-total gradient-causal misalignment.